Machine Learning
We describe here the basic neural language models used to model language - Recurrent Neural Networks. For this part and the remaining work, we represent scalars with normal font \( x\), vectors in bold \(\boldsymbol{x}\), and matrices in capitalized bold \( \boldsymbol{X} \).
Recurrent Neural Networks (RNNs)
To learn the parameters of neural language models we used Recurrent Neural Networks (RNNs), which are a type of neural networks designed to process sequential data, where the input's size does not need to be fixed (Bengio et al, 2016). Since language shows an inherent sequential structure, and by empiricists' believe, it has an underlying joint probability distribution, RNNs are well suited for the language modelling task.
A RNN is a feed forward neural network extended over time, governed essentially by the equation that relates the hidden state \(\boldsymbol{h}\) of the network at time \(t\), with the previous hidden state at time \(t-1\), the current input \(\boldsymbol{x}\) at time \(t\) and the set of network parameters \(\theta\):
$$ \boldsymbol{h}^{(t)} = f(\boldsymbol{h}^{(t-1)}, \boldsymbol{x}^{(t)}; \theta) $$From this relation we notice that a RNN is by construction a recursive function, where the hidden state changes with time, but the parameters are fixed and shared. Morevover, since \(\boldsymbol{h}^{(t)}\) depends on \(\boldsymbol{h}^{(t-1)}\), the hidden state is sometimes regarded as the model's memory, because (in theory) it stores the information from all the previously processed inputs.
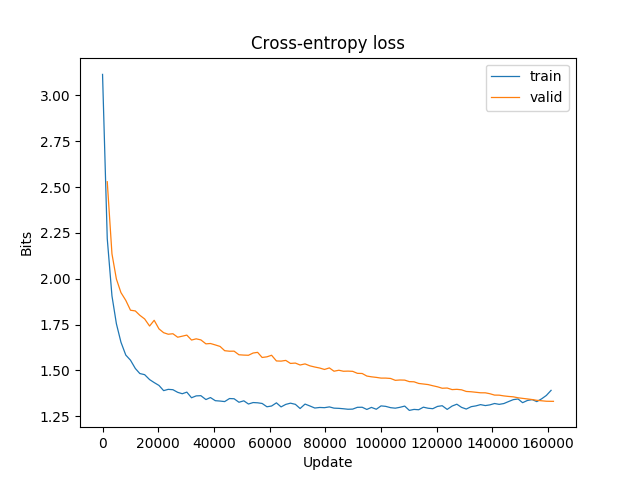
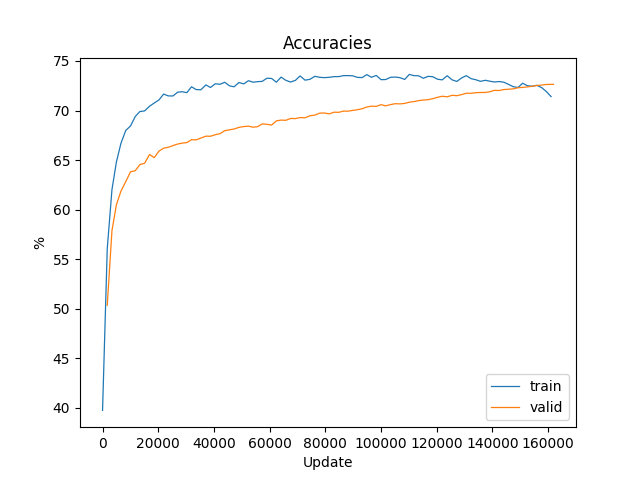
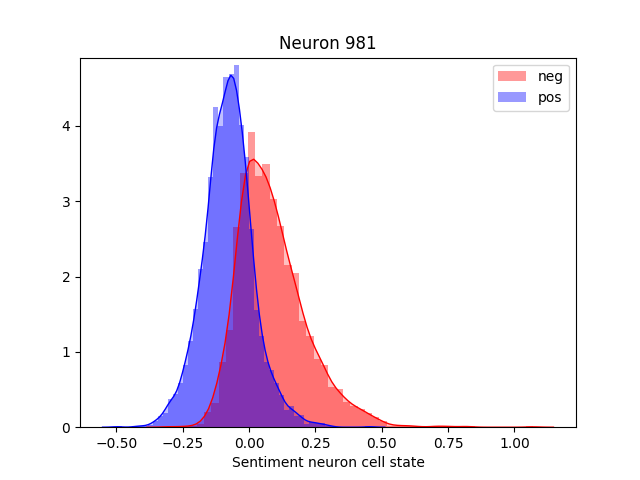
In the byte-level language modelling problem we are interested in describing how a byte is deduced from previous ones. For this task, we used an RNN architecture that produces an output at each time step and has recurrent connections between hidden units. The following picture and equations depict this idea:

Here the set of parameters \(\theta\) to be learned are the matrices \(\boldsymbol{U}\), \(\boldsymbol{W}\) and \(\boldsymbol{V}\) (we do not account biases separetely), which represent the input-to-hidden, hidden-to-hidden and hidden-to-output linear connections. As with feed forward neural networks, the hidden state is the result of linear transformations (given by matrices \(\boldsymbol{U}\) and \(\boldsymbol{W}\)) followed by a non-linear activation function (hyperbolic tangent). To clarify the dimensions of these matrices, consider that \(V\) is the input / ouput vocabulary size and \( D \) is the size of the hidden-state. Then, the input-space is in \(\mathbb{N}^{V}\), the feature-space in \(\mathbb{R}^{D}\) and the output-space in \(\mathbb{R}^{V}\). Also, for simplicity, we assume that only one input is fed at a time (in constrast to a batch of inputs). We obtain \(\boldsymbol{x} \in \mathbb{N}^{V}\), \(\boldsymbol{h} \in \mathbb{R}^{D}\), \(\boldsymbol{o} \in \mathbb{R}^{D}\), \(\boldsymbol{y} \in \mathbb{R}^{D}\), \(\boldsymbol{U} \in \mathbb{R}^{D \times V}\), \(\boldsymbol{W} \in \mathbb{R}^{D \times D}\) and \(\boldsymbol{V} \in \mathbb{R}^{V \times D}\).
Considering \(\boldsymbol{X} = \boldsymbol{x}^{(1)} \ldots \boldsymbol{x}^{(n)} \) as the network input and \(\boldsymbol{Y} = \boldsymbol{y}^{(1)} \ldots \boldsymbol{y}^{(n)} \) the network output, the loss we want to minimize is the sum of the losses at each time \( t \), \(L^{(t)}\), which is the cross-entropy between \(\boldsymbol{y}\) and \(\hat{\boldsymbol{y}}\):
\begin{align} L (\boldsymbol{y}^{(1)} \ldots \boldsymbol{y}^{(n)}; \boldsymbol{x}^{(1)} \ldots \boldsymbol{x}^{(n)}) & = \sum_{t=1}^n L^{(t)} \\ & = -\sum_{t=1}^n \log p (\boldsymbol{y}^{(t)} | \boldsymbol{x}^{(1)} \ldots \boldsymbol{x}^{(t)}) \\ & = -\sum_{t=1}^n \log (\hat{\boldsymbol{y}}^{(t)}[\boldsymbol{y}^{(t)} == 1]) \end{align}In the equation above \(\hat{\boldsymbol{y}}^{(t)}[\boldsymbol{y}^{(t)} == 1]\) denotes the entry of \(\hat{\boldsymbol{y}}^{(t)}\) where \(\boldsymbol{y}^{(t)}\) is equal to 1. Minimizing the cross-entropy loss is the same as maximizing the log-likelihood (the logarithm is used for numerical stability). Intuitively, the cross-entropy between random variables \(p\) and \(q\), denoted by \(H(p, q)\), measures the average number of bits needed to represent a symbol from \(p\), given that its coding scheme was derived with the probability distribution governing the random variable \(q\). If \(q\) follows the exact same distribution as \(p\), then the cross entropy is the entropy itself. Moreover, this also yields the minimization of the Kullback–Leibler divergence - a measure of how distant two probability distribution are. In the end, we want the estimated probability distribution \(\hat{\boldsymbol{y}}^{(t)}\) to be as close as possible to the true one \(\boldsymbol{y}^{(t)}\).
Training RNNs
Similar to feed forward neural networks, RNNs parameters are updated by a gradient descent method. For example, parameter \(\boldsymbol{W}\) is updated as:
$$ \boldsymbol{W} \leftarrow \boldsymbol{W} - \eta \nabla_{\boldsymbol{W}} L $$Where \(\eta\) is the learning rate and \(\nabla_{\boldsymbol{W}} L\) the derivative of the loss with respect to the weigths \(\boldsymbol{W}\). In our experiments we used a variation of the traditional gradient descent, the ADAM method (Kingma et al, 2014). Also, from the multiple ways to update the learning rate during training, we chose to linearly decay the initial learning rate to zero throughout the iterations. In feed forward NNs, the gradients \( \nabla_{\boldsymbol{W}}\) are computed using a dynamic programming approach called back-propagation (Bengio et al, 2016). The difference of computing gradients of RNNs and feed forward NNs is that the back-propagation is done through time - Back-Propagation Through Time (BPTT). This means that a parameter is updated by adding all the contributions to the loss over time. For instance, the derivative of the loss with respect to the output matrix \(\boldsymbol{V}\) is given by (Bengio et al, 2016):
$$ \nabla_{\boldsymbol{V}}L = \sum_{t}(\nabla_{\boldsymbol{o}^{(t)}}L)\boldsymbol{h}^{(t)} $$Two problems related to the gradient computation arise when training RNNs (Pascanu et al, 2013): vanishing and exploding gradients. They appear because when computing the gradient of the loss at time \(t\) with respect to the parameters, a sum over \(k\) of the terms \( \frac{\partial \boldsymbol{h}^{(t)}}{\partial \boldsymbol{h}^{(k)}} = \prod_{t \geq i > k} \frac{\partial \boldsymbol{h}^{(i)}}{\partial \boldsymbol{h}^{(i-1)}} \) arises (see (Pascanu et al, 2013) for a detailed derivation). Since \( \frac{\partial \boldsymbol{h}^{(t)}}{\partial \boldsymbol{h}^{(t-1)}} = \boldsymbol{W} \tanh'(\boldsymbol{W} \boldsymbol{h}^{(t-1)}) \), the product from the previous equation results in a term equal to \( \boldsymbol{W}^{t-k} \). The vanishing gradient problem comes from the fact that, assuming \(\boldsymbol{W}\) to have an eigendecomposition, the eigenvalues of \(\boldsymbol{W}\) that are less than 1 decrease exponentially to zero with \( t \), while the exploding gradient problem exists if the eingenvalues are greater than 1. Both situations are not desirable when training the network. The first one leads to a slower convergence, while the latter can move the gradient descent trajectory out of the descent path.
A practical solution for the exploding gradients proposed in (Pascanu et al, 2013) is to clip the gradients if they are higher than a threshold (empirical value), by scaling the gradient, but keeping its direction. A solution to the vanishing gradients is to not propagate the loss through all time steps, but to perform a Truncated Back-Propagation Through Time (TBPTT). In this setting, instead of training on a whole sequence \(\boldsymbol{X} = {\boldsymbol{x}_1, \ldots, \boldsymbol{x}_n}\) from \(1\) to \(n\), we choose a value \( 1 \leq \tau \leq n \), for which when computing the loss we only consider the sequence from \(\tau\) to \(n\). Naturally, TBPTT also accelerates the training procedure. A second approach is to use another type of RNN architecture, the Long Short-Term Memory (LSTM) architecture, which we mention in a section below.
Using Truncated Back-Propagation Through Time there are two possibilities to deal with hidden state of the RNN when moving between training batches. In stateful RNNs we have reason to believe that the dependencies in the data span over the truncated sequence, so we keep the hidden state across batches in order to simulate a full back-propagation. While in stateless RNNs, the hidden state is reseted after processing a training sequence, if the there are no long term dependencies in the data.
In our experiments, we used the TBPTT to solve the vanishing gradient and memory related problems, and we used stateful RNNs, because in a language modelling task, we wish to keep the long range information from previously processed text.
Sampling RNNs
In the context of language modelling, sampling means generating the next word (or byte) based on the history processed so far. The inputs are a text to start sampling from, denoted by prime \(\boldsymbol{P} = \boldsymbol{p}_1 \ldots \boldsymbol{p}_m \), where \( \boldsymbol{p}_i \) is a one-hot encoded vector of the vocabulary's size, and the number of words to sample \(n > m\). With the pre-trained parameters, we begin with an initial hidden state \( \boldsymbol{h}^{(0)} = \boldsymbol{0} \) and input \( \boldsymbol{x}^{(1)} = \boldsymbol{p}_1 \), and compute the hidden states until \(m\) by using the previous hidden state and by taking each input from \( \boldsymbol{P} \) sequentially. To process the words after the \(m^{\text{th}}\) word, we predict the words \( m+1 \) to \( n \) as an index \(k\) of the prediction vector \( \hat{\boldsymbol{y}}^{(j)} \), which we use as input to the prediction of the next word, i.e., \( \forall j > m \text{, } \boldsymbol{x}^{(j+1)} = \boldsymbol{\hat{y}}^{(j)} \).
For every time step \(t\) we pick a value from \(\hat{\boldsymbol{y}}^{(t)}\), the vector resulting from the softmax operation of the output vector \(\boldsymbol{o}^{(t)}\). The softmax function is used as an extension of the sigmoid function to multiple variables, transforming its input into a probability distribution over the possible discrete outputs:
$$ \hat{y}_i^{(t)} = \text{softmax}(o_i^{(t)}) = \frac{\exp(o_i^{(t)})}{\sum_{i=1}^V \exp(o_i^{(t)})} $$Thus, \(\hat{\boldsymbol{y}}^{(t)}\) represents the probability distribution over the words indexed with \(0 \leq i \leq V-1\). Our language model will then pick a word from this probability distribution. For that we found two different approaches:
- Take the word with maximum probability. Simply take the index of \(\hat{\boldsymbol{y}}^{(t)}\) as \( i = \underset{i}{\arg\max} \text{ } \hat{\boldsymbol{y}}^{(t)} \). With this approach we observed that the sampling process enters a looping state and outputs repetitive text.
- Take the word as a sample from the multinomial distribution represented by \( \hat{\boldsymbol{y}}^{(t)} \). In this case the model picks the index \( i \) with probability \( \hat{\boldsymbol{y}}_i^{(t)} \). We observed that, contrary to taking the maximum probability, this approach prevents the sample to loop. Additionally, for sampling, one can introduce another parameter called temperature (Hinton et al, 2015). Temperature (\( T \)) is a parameter used to control the randomness of the predictions. With this parameter each entry of the vector \( \hat{\boldsymbol{y}}^{(t)} \) is modified to:
$$
\hat{y}_i^{(t)} = \text{softmax}(o_i^{(t/T)}) = \frac{\exp(o_i^{(t/T)})}{\sum_{i=1}^V \exp(o_i^{(t/T)})}
$$
If \( T \) grows to infinity, \( \boldsymbol{\hat{y}} \) results in an uniform distribution and all predictions are equally likely. If \( T\) is equal to 1, we obtain the traditional model. If \( T\) tends to 0, we obtain the sampling from the maximum probability variant. Thus, with lower temperatures the model is more conservative, and is not likely to generate random sentences. On the other hand, higher temperatures result in more diversity in the output, at the cost of more syntax mistakes.
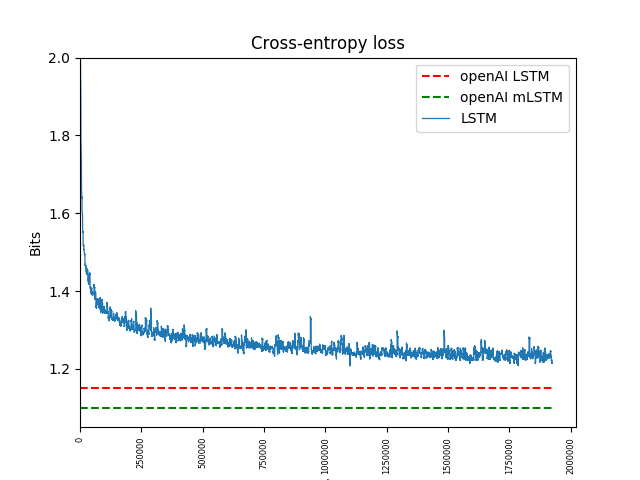
Long Short-Term Memory Networks (LSTMs)
As previously explained, simple RNNs suffer from the vanishing and exploding gradient problems. LSTM networks (Schmidhuber et al, 1997) share the same principles of RNNs, but their architecture prevents these two identified problems. So, they are capable of learning long-term dependencies more effectively than traditional RNNs. For this reason, we used in our language model this type of architecture.
While RNNs' hidden states are computed using a linear transformation followed by a non-linearity, LSTMs replace this computation with LSTM cells, and additionally to the hidden state they introduce a cell state. Intuitively, the hidden state can be perceived as the working (short term) memory and the cell state as the long term memory. The inputs to LSTMs cell are: the previous hidden state \(\boldsymbol{h}^{(t-1)}\); the previous cell state \(\boldsymbol{c}^{(t-1)}\); and the current input \(\boldsymbol{x}^{(t)}\). The outputs are: the current hidden state \(\boldsymbol{h}^{(t)}\); and the current cell state \(\boldsymbol{c}^{(t)}\). The output prediction is computed as with RNNs by performing a linear operation with the hidden states followed by a softmax function. The following equations define LSTMs in general:
\begin{align} \boldsymbol{f}^{(t)} & = \sigma (\boldsymbol{W}_f [\boldsymbol{h}^{(t-1)}, \boldsymbol{x}^{(t)}]) \\ \boldsymbol{i}^{(t)} & = \sigma (\boldsymbol{W}_i [\boldsymbol{h}^{(t-1)}, \boldsymbol{x}^{(t)}]) \\ \boldsymbol{c}^{(t)} & = \boldsymbol{f}^{(t)} \cdot \boldsymbol{c}^{(t-1)} + \boldsymbol{i}^{(t)} \cdot \tanh (\boldsymbol{W}_c [\boldsymbol{h}^{(t-1)}, \boldsymbol{x}^{(t)}]) \\ \boldsymbol{o}^{(t)} & = \sigma (\boldsymbol{W}_o [\boldsymbol{h}^{(t-1)}, \boldsymbol{x}^{(t)}]) \\ \boldsymbol{h}^{(t)} & = \boldsymbol{o}^{(t)} \cdot \tanh(\boldsymbol{c}^{(t)}) \end{align}Where \( [\boldsymbol{h}^{(t-1)}, \boldsymbol{x}^{(t)}] \in \mathbb{R}^{D+V} \) represents the concatenation of hidden states and input. \( \sigma (.) \) is the sigmoid function. \( \boldsymbol{W}_f, \boldsymbol{W}_i, \boldsymbol{W}_c, \boldsymbol{W}_o \in \mathbb{R}^{D \times (D+V)} \) are the parameters to be learned. \( \boldsymbol{f}^{(t)}, \boldsymbol{i}^{(t)}, \boldsymbol{c}^{(t)}, \boldsymbol{o}^{(t)}, \boldsymbol{h}^{(t)} \in \mathbb{R}^{D} \).
The training and sampling processes of LSTMs are very similar to RNNs, and so we won't detail them here. For further information we redirect the reader to (Bengio et al, 2016).
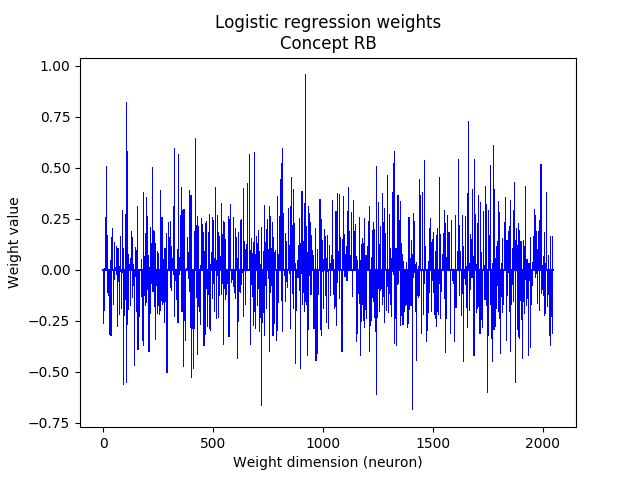
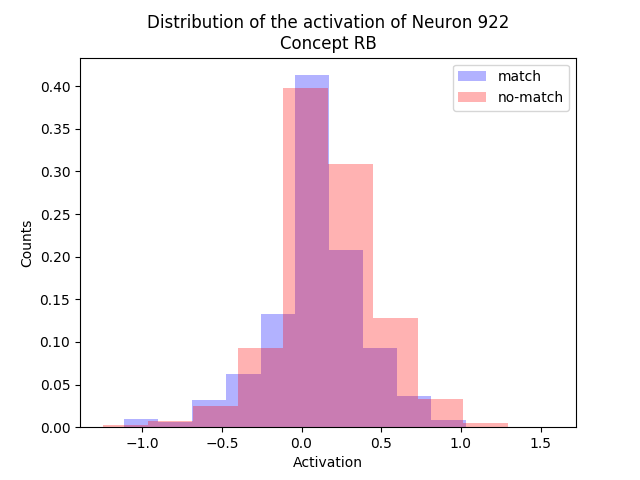
Logistic Regression
Logistic regression is a model used for supervised classification tasks, based on a linear model followed by a non-linearity. In a binary classification setting with classes 0 and 1, the output of the logistic regression can be interpreted as a probability of belonging to one of the classes. Specifically, if \( \boldsymbol{x} \in \mathbb{R}^{1 \times D} \) is our input vector, the estimated output \( \hat{y} \in \mathbb{R} \) is given by:
$$ \hat{y} = \sigma(\boldsymbol{x}\boldsymbol{W} + b) $$Where \( \boldsymbol{W} \in \mathbb{R}^{D \times 1} \) and \( b \in \mathbb{R} \) are model parameters, and \( \sigma(a) = 1 / (1 + e^{-a}) \) is the sigmoid function, which forces the output to be in the interval \( [0, 1] \).
For \( N \) data points, the loss function to minimize is given by the negative log-likelihood, or as explained before, the cross-entropy:
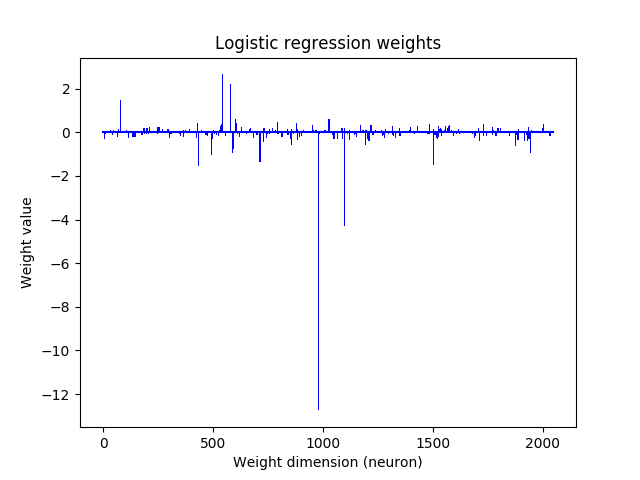
$$ L(\boldsymbol{y}, \boldsymbol{\hat{y}}) = \sum_{i=1}^{N} -y_i\log(\hat{y}_i) - (1-y_i) \log(1 - \hat{y}_i) $$To prevent overfitting it is common practice to use a regularizer to penalize the loss function. We used a \( L_1 \) regularizer to enforce sparse models, which results in the loss:
$$ L_R = L(\boldsymbol{y}, \boldsymbol{\hat{y}}) + \lambda \sum_{i=1}^D |W_i| $$Where \( \lambda \) is the regularization coefficient. With this loss function there is no analytical solution for deriving the parameters. However, they can be efficiently computed using a gradient descent approach.
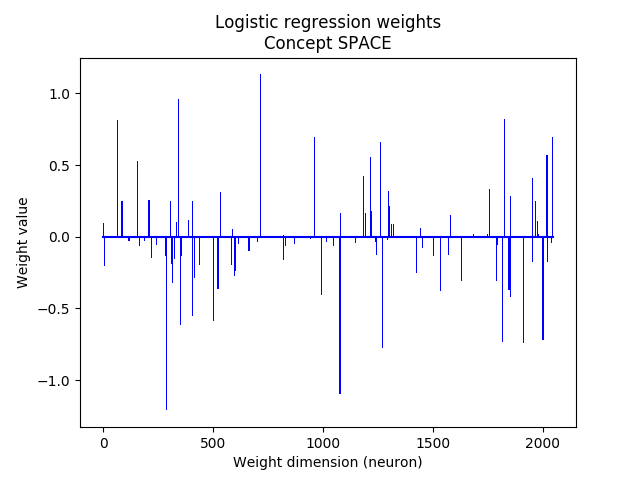
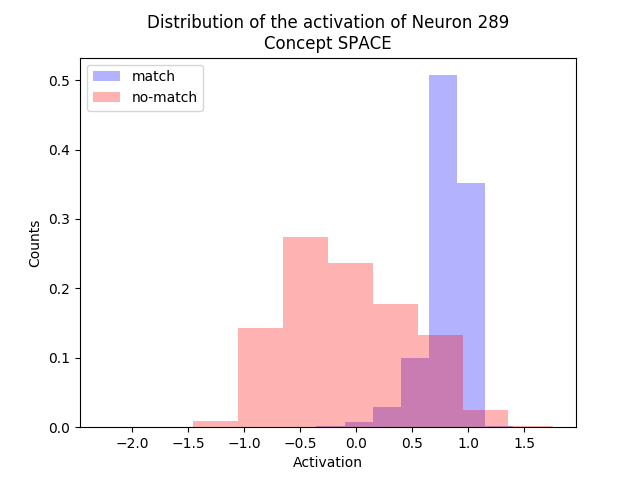
Multiclass logistic regression
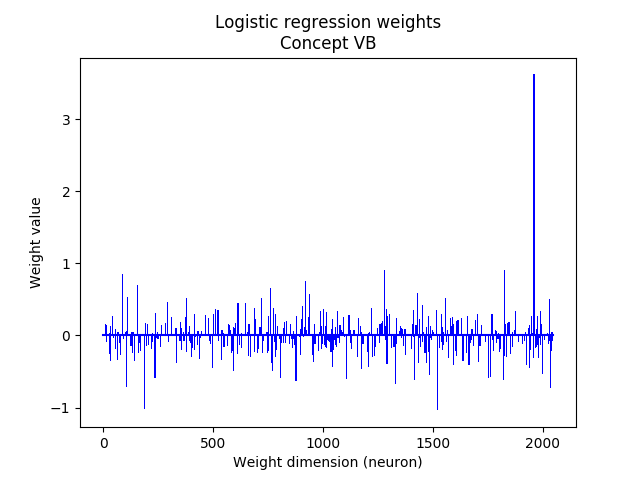
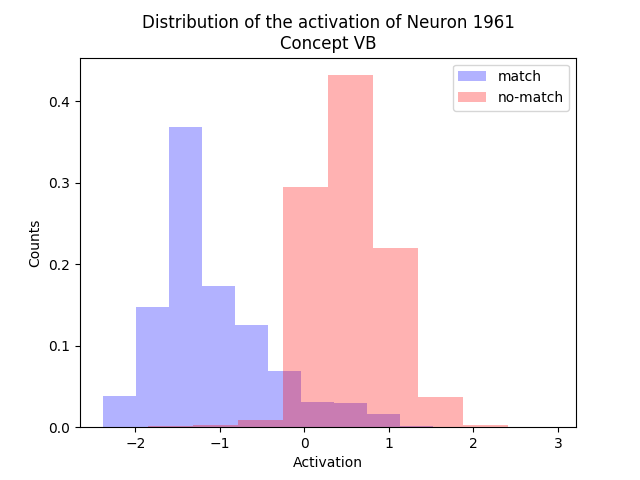
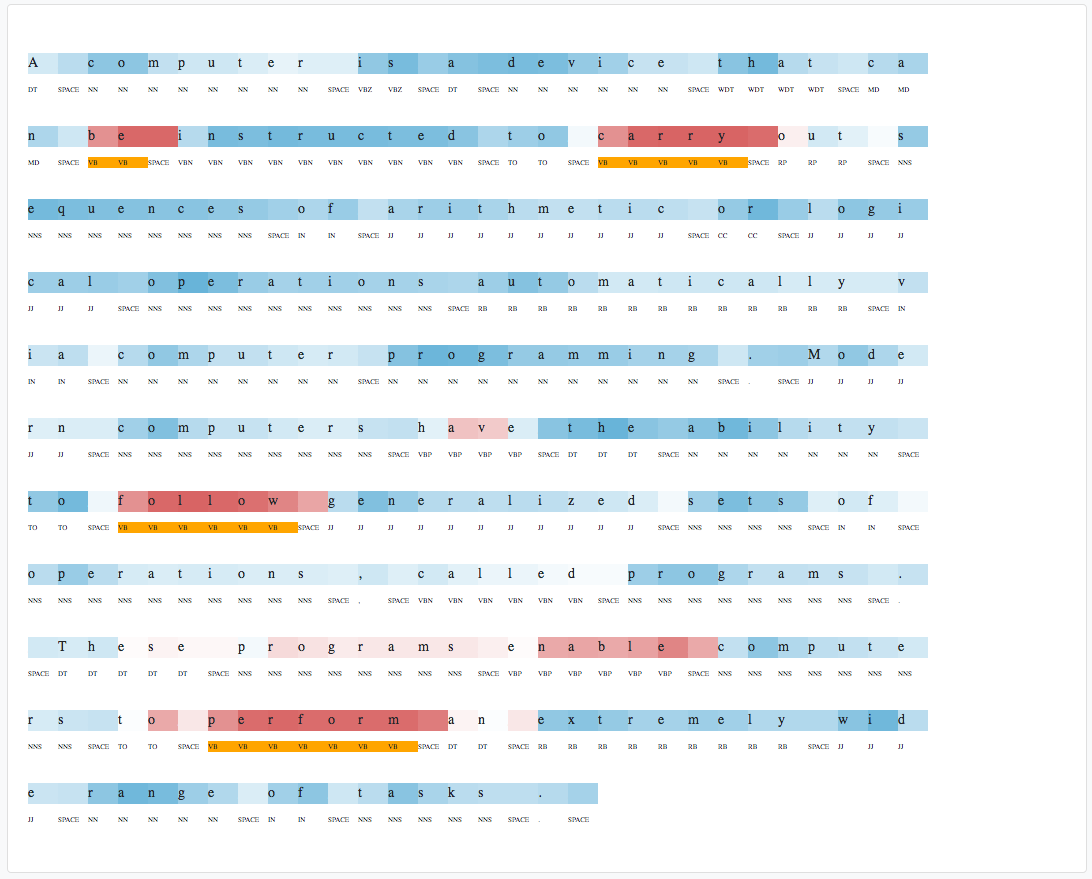
In the multiclass setting there are labels with \(C\) distinct classes. One way to train such a model is to separately train \( C \) classifiers in a One-vs-All approach, which can be trained in parallel. To infer the class \(j \in \{1, \ldots, C\}\) of a new unseen datapoint \( \boldsymbol{x} \) we simply compute:
$$ j = \underset{j = 1, \ldots, C}{\arg\max} \text{ } \boldsymbol{x} \boldsymbol{W}_n^{(j)} + b_n^{(j)} $$Where \( \boldsymbol{W}_n^{(j)} = \boldsymbol{W}^{(j)} / \left\lVert \boldsymbol{W}^{(j)} \right\rVert _2 \) and \( b_n^{(j)} = b^{(j)} / \left\lVert \boldsymbol{W}^{(j)} \right\rVert _2 \) are the normalized pre-trained parameters.
Evaluation metrics
To evaluate the results of a classifier we used three common metrics: accuracy; precision; and recall. In the next table we show the confusion matrix, and how each metric is computed.
| True class | |||
|---|---|---|---|
| Correct | Not Correct | ||
| Predicted class | |||
| Selected | True Positives (TP) | False Positives (FP) | |
| Not Selected | False Negatives (FN) | True Negatives (TN) | |
\( \text{Accuracy} = \frac{\text{TP + TN}}{\text{TP + FP + TN + FN}} \), is the fraction of predictions the model got right.
\( \text{Precision} = \frac{\text{TP}}{\text{TP + FP}} \), is the fraction of selected items that are correct.
\( \text{Recall} = \frac{\text{TP}}{\text{TP + FN}} \), is the fraction of correct items that are selected.
Implementation details
The language models based on LSTMs were implemented in Tensorflow using simple matrix multiplications (we only left the gradient computation to the Tensorflow optimizer routine). For classification tasks, we used the logistic regression classifier module from the PYTHON package sickit-learn.