Project Information
| Project name | Deepdive |
| University | Albert-Ludwigs Universität Freiburg |
| Department of Project | Chair of Algorithms and Data Structures |
| Supervisor | Elmar Haussmann |
| Participants | Louis Retter & Frank Gelhausen |
Project Description
This project consisted of getting to know Deepdive aswell as finding out how well it performs and finding possible use cases. Deepdive is a data-managament system which can extract entities from a given text and predicts the probablility of entities engaged in a given relation using machine-learning. These predictions are based on user-defined features, not algorithms, which is the main advantage of using Deepdive over other systems.
Process
Step One
During the first week our focus was on reading the Deepdive documentation and installing all the necessary software on the provided server. After finishing the setup, the first step was to create a working example based on the tutorial provided by Deepdive. The tutorial consisted of using a simple input text of one-line sentences. We then extracted entities from the text using a freebase-dataset. In this case, we were only interested in persons. The goal was then to find all the married couples in the text using Deepdive.
Step Two
After having completed the tutorial and having understood the basic usage of Deepdive, we assumed that Deepdive could be used to create an interactive web application, consisting of using uploaded text files to predict and highlight extracted relations defined by the user. The idea was to use this to find relations inside of books and other school material. Although the NLP-extractor used to identify entities inside sentences is very efficient, it is not fast enough to be used inside a real-time application.
Step Three
After the failed attempt to use the framework in a real-time web application, we decided instead to build simple template using Deepdive that could easily be extended to accept any given relation. We were provided with a large input file (66GB) of example sentences, which we reduced to an acceptable size. Based on this input file, we then first created a file containing positive examples of person-nationality relations. After adapting the features to match this new relation, we tried to run Deepdive, but noticed that the nlp-extractor took a long time to process even a small amount of the sentences.
We then decided to skip the nlp-extraction step and instead use the already extracted sentences, which were also included in the provided file. This increased the speed of the system dramatically. This also gave us the possibility to compare the results using the nlp-extractor to the ones using the wikipedia-entities provided by the input file.
Up until now we used Deepdive excluding the nlp-extractor to generate all necessary database tables. In the next step we created these tables using the input file. The necessary scripts can be found in the Download section. Then we defined custom features fitting the person-nationality relation and were able to run the program.
Example implementation
To illustrate how to use and expand our project, we will now guide you through each single step. We will use the person-nationality relation as an example. Use the Quick Start to install Deepdive and set up the necessary folder structure.
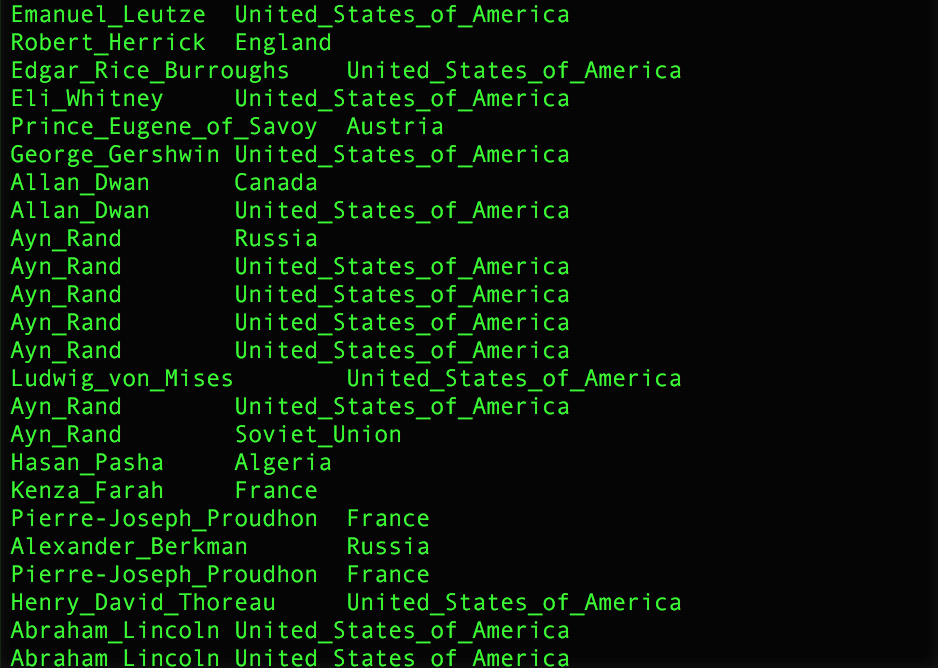
1) Create positive examples
First you need to create a .tsv-file containing a number of positive examples for the desired relation. (Here: person-nationality relation)
2) Update schema.sql and initialize database
Now you can modify our schema.sql provided in the download section by adding a block of code similar to the following for each desired relation:
DROP TABLE IF EXISTS has_nationality_features CASCADE;
CREATE TABLE has_nationality_features(
relation_id text,
feature text);
Now you can run deepdive init db to initialize the tables. (use export PATH=~/local/bin:"$PATH" to enable deepdive command) Using deepdive sql '\d+' you can see a list of all the created tables.
3) Generate sentences-table
Now you need an input file containing sentences that you wish to check for relations, similar to the one provided in the download section (entity_sentences_reduced.txt). If you do not have a file containing already parsed sentences, you can use an nlp-extractor to get the same results. The script buildSentencesTable.py reads through the input file and fills the sentences table with the extracted data. You can execute it by running deepdive run buildSentences, as defined in deepdive.conf. You can now see the content of the table using deepdive sql "SELECT * FROM sentences;".
4) Extract entity_mentions-table
Next run the python script buildEntitiesTable.py to extract all the entities (PERSON, DATE, LOCATION, ...) from the sentences.
5) Add a relation extractor to deepdive.conf
For each desired relation, you will need to add a custom extractor to deepdive.conf. As a reference, you can use the extractor for the has_nationality
relation.
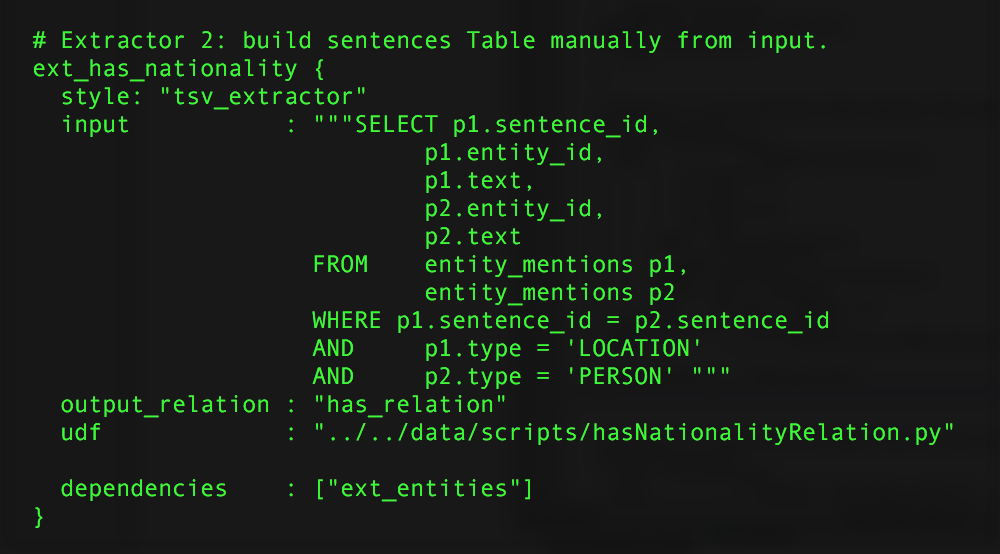 When running the command deepdive run hasNationality (or your custom command, defined in the pipelines section in deepdive.conf), this extractor will run the python script referenced by 'udf' on the input generated by the Sql-query.
The script will then insert the result to the table mentioned in 'output_relation'. To adapt the python script hasNationalityRelation.py for your own relation,
you will have to change the name to your relation in the print statement at the end.
When running the command deepdive run hasNationality (or your custom command, defined in the pipelines section in deepdive.conf), this extractor will run the python script referenced by 'udf' on the input generated by the Sql-query.
The script will then insert the result to the table mentioned in 'output_relation'. To adapt the python script hasNationalityRelation.py for your own relation,
you will have to change the name to your relation in the print statement at the end.
6) Add a feature extractor to deepdive.conf
Similar to the previous step, you have to costumize the sql query of the extractor to fit your relation and define the location of your python script that defines the features to be used.
Also set the 'output_relation' to the table specified in schema.sql. In our case this was "has_nationality_features".
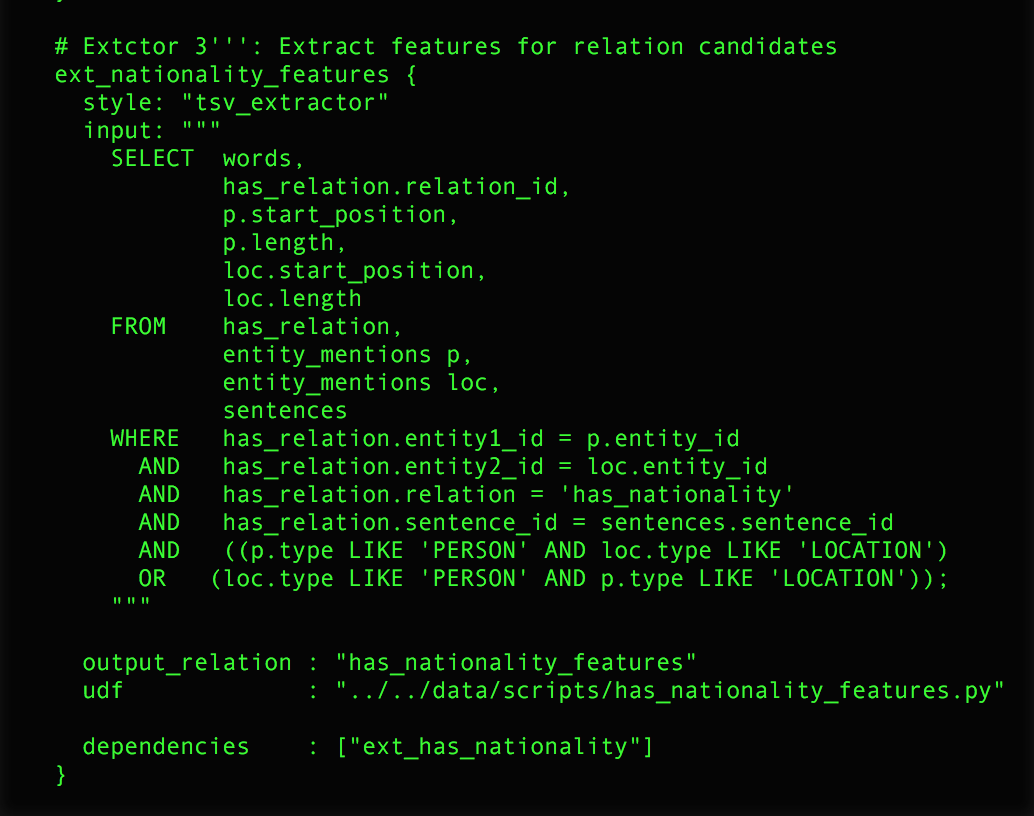
7) Define features and inference rules
Now you have to define features specific to your relation. You can find an example in has_nationality_features.py. These features will be used by Deepdive to predict the probablity of a relation. As a final step that enables Deepdive to make predictions, you will have to add 'inference rules' for each relation. An example of such an inference rule can be found in our example deepdive.conf.
8) Run the final program
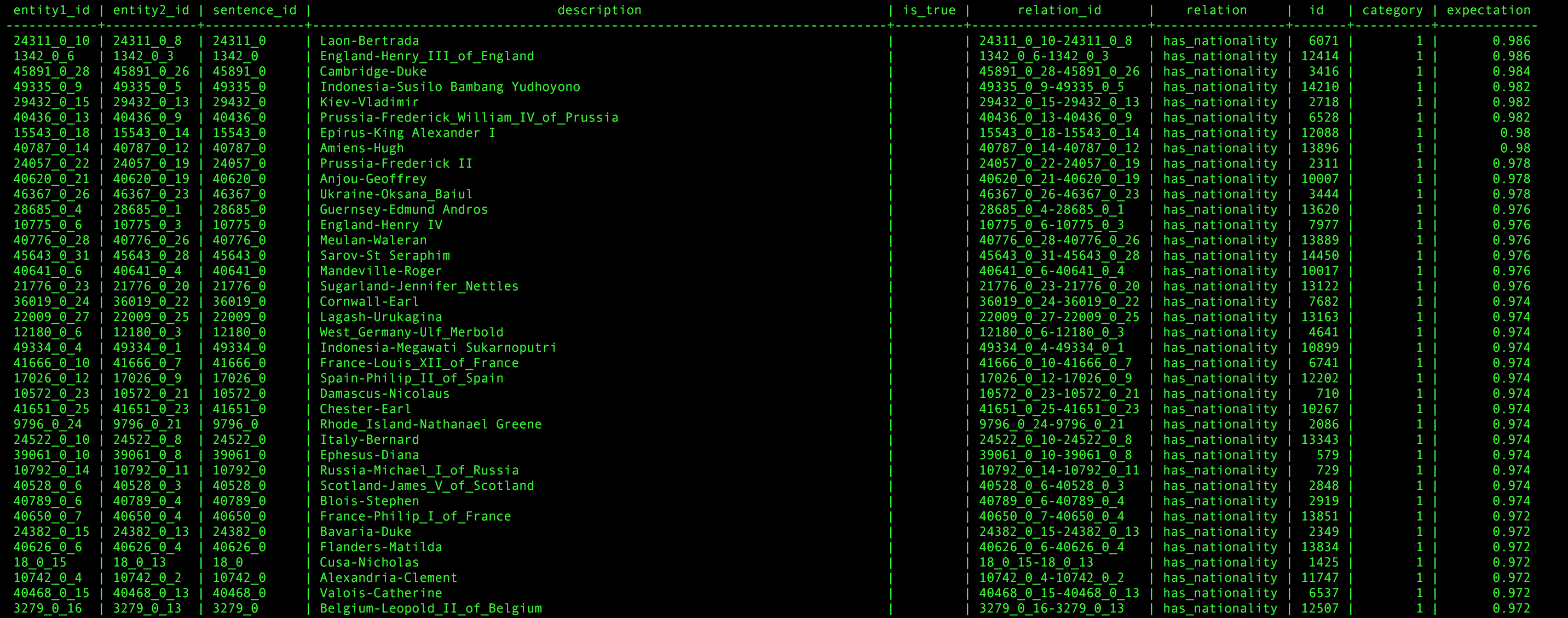
Now you can run the command deepdive run All or use all the pipelines in a row. This will result in a table containing the predictions made by Deepdive.
To see the results, simply enter the following command: deepdive sql "SELECT * FROM has_relation_is_true_inference;"
Conclusion
Based on our experience, Deepdive can not be used in a real-time application due to the computation time of the nlp-extractor, but based on a large database of positive and negative examples and well defined features, Deepdive is able to very efficiently identify new entitiy tuples engaged in a specific relation. Although the idea of using features instead of algorithms simplifies the understanding by the user, it is sometimes difficult to come up with meaningful features.