Experiments¶
In the following results of experiments made during the project are documented.
Getting Html pages¶
Using endSly/world-universities-csv as a source for university websites we downloaded 38.517.248 html sites from the March 2017 CommonCrawl archive. See Common Crawl for more details.
Categorizing the pages¶
To binary label the Html pages into Personal page and No personal page the first step was to get features for
the classification. A first guess was to use the Bag-of-words
approach with the text content of the page.
Later this was improoved using uni-, bi- and trigrams and url
features as suggested by [DasG2003].
Remove Bioilerplate from Html¶
To retrieve the relevant text it is necessary to remove html boilerplate first. There are many algorithms aviable to do this task. One of the boilerplate removal algorithms is JusText which was used in this project. The algorithm categorizes the Html content into the categories
- bad
- short
- neargood
- good
of which we only considered good labeled parts for the features.
Url Parameters¶
As suggested by [DasG2003] one can divide the categorization into two views: Content-based and URL-based. Coming from the idea, that one might decide if a URL leads to a personal page
e.g. https://cs.example.edu/staff/~janedoe
the following features where used:
- Take the URL-path and split by
/. - Replace
~bytilde. - Replace words not in enchant dictionary
en_USwithnodict. - Replace a hyphenated word (e.g. computer-science) by
hyphenatedword - Replace numeric parts (e.g.
/12353/) bynumeric - Prefix parts with
urlparam.
See also helpers.get_url_parameters_as_text for implementation.
Creating a training set¶
In the following we use supervised learning to categorize the Web pages. Therefore we created a training set containing positive and negative samples.
The first 1000 positive researcher homepage examples where labeled by hand. About another 1000 positive examples came from [WebKB].
The [dblp] database provides researchers homepages as described here to get more meaningful results, the homepages where filtered against a list of social network like hosts:
- github.com
- facebook.com
- orcid.org
- dl.acm.org
- viaf.org
- zbmath.org
- andrej.com
- uk.linkedin.com
- researcher.watson.ibm.com
- de.linkedin.com
- awards.acm.org
- de.wikipedia.org
- www.cs.cmu.edu
- id.worldcat.org
- andrej.com
- research.microsoft.com
- researchgate.net
- researcherid.com
- lattes.cnpq.br
- zpid.de
- twitter.com
- www.scopus.com
- d-nb.info
- sites.google.com
- isni.org
- www.linkedin.com
- id.loc.gov
- zbmath.org
- www.genealogy.ams.org
- viaf.org
- www.wikidata.org
- en.wikipedia.org
- dl.acm.org
- orcid.org
- scholar.google.com
This added another 29899 positive labeled examples. The full list is aviable in
To generate negative examples we randomly have chosen samples from the archive and then removed false positives by hand. The script generate_learning_sets.py generates the training sets.
Train SVM for Web page classification¶
We chose SVM to do the binary classification into personal Web Pages and non personal Web pages. The scikit-learn toolkit used provides implementation of most of the common learning models. As mentioned before we used 1, 2, and 3-grams as features. In addition we used tf-idf.
So our scikit-learn pipeline ended up like this:
Pipeline([('vect', CountVectorizer(min_df=0.005,
max_df=0.3,
ngram_range=(1, 3))),
('tfidf', TfidfTransformer()),
('clf', SGDClassifier(loss='hinge',
penalty='l2',
alpha=1e-3,
n_iter=5,
random_state=42,
verbose=100)), ])
Classification Results using linear SVM¶
Using the training set splitted into 90% training and 10% to test the linear SVM results are shown in Table 1: Linear SVM classifier evaluation..
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| No personal page. | 0.92 | 0.98 | 0.95 | 1873 |
| Personal page. | 0.96 | 0.84 | 0.89 | 931 |
| avg / total | 0.94 | 0.93 | 0.93 | 2804 |
| support = Number of occurrences of each label in the ground truth | ||||
Using the coefficients for the support vectors which are orthogonal to the hyperplane the svm is using to divide the data, we can use their sign which indicates the predicted class and the relation of their absolute values to determine feature importance. The results are shown in figure 1.
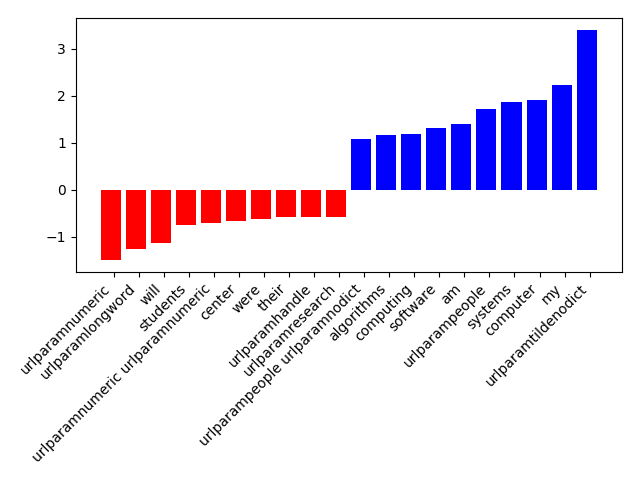
Figure 1: Top 10 features. Blue = Personale Page, red = No personal page
As we can see here, there are some features we would not expect in the top range like computer or algorithms.
The reason is, that the dblp and WebKB used as positive personal Web page samples mostly origin from a computer
science background. So the classifier has a strong bias towards computer science. To get a more neutral classifier it
would be crucial to equal out the training set. Another possibility which does not involve to search for thousands of
personal Web pages by hand is to start with a smaller unbiased training set and use co learning techniques.
Information Extraction¶
After identifying personal homepages the next step is to extract some information of the persoon the homepage is about. In this project, the main focus was to extract the following data from the researchers homepages:
- Name
- Profession
- Affiliation
- Gender
Extract the name¶
To extract the the name one has to first mark all names appearing on the homepage. This is known as Named-entity recognition and in this case means to identify person names. E.g. take the input
Hi, I am Jane Doe and a member of FOO coorporation.
and produce the marked text
Hi, I am <person>Jane Doe</person> and a member of FOO coorporation.
To achieve this the Stanford Named Entity Recognizer (Stanford NER) was used. The model Stanford NER uses is similar to the baseline local+Viterbi model in [FGM2005].
After marking all person names in the homepages it has to be decided which is the correct one - the name of the person this particular page is about. To solve this task we mainly used information about the position of the name and occurrences in headings or the title. So we created a feature vector like
where \(t, h_i, s_i \in \{0, 1\}\) and a \(1\) means, that \(name\) occures in the title (\(t\)) or \(i\)-th heading/sentence (\(h_i\))/(\(s_i\)). With this we created a training set of 146 labeled examples and trained a SVM on 90% of the data using 10% to test the classifier. The results are shown in Table 2: Performance Name entity selection..
| precision | recall | f1-score | support |
|---|---|---|---|
| 0.94 | 0.93 | 0.93 | 15 |
Extract the profession¶
For retrieving the profession we used a bag of words approach.
As data the text content was used and a training set of 129 examples created which can be found in data/ppe_training_set.
Additional labeled data can be created with src/generate_profession_gender_labeled_training_set.py. This training data
was used to train a SVM classifier. Results are shown in Table 3: Performance of profession multiclass SVM classifier..
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| graduate. | 0.50 | 0.67 | 0.57 | 6 |
| postdoc. | 0.79 | 0.85 | 0.81 | 13 |
| professor. | 0.75 | 0.43 | 0.55 | 7 |
| avg / total | 0.71 | 0.69 | 0.69 | 26 |
| support = Number of occurrences of each label in the ground truth | ||||
The poorer performance is probably because of the relatively small training set and some present clustering in the training set. The figures 2, 3, 4 also show, that the categorization learned some unintended clustering. To avoid this one may have to label a bigger training set and introduce a improved stopwords list.
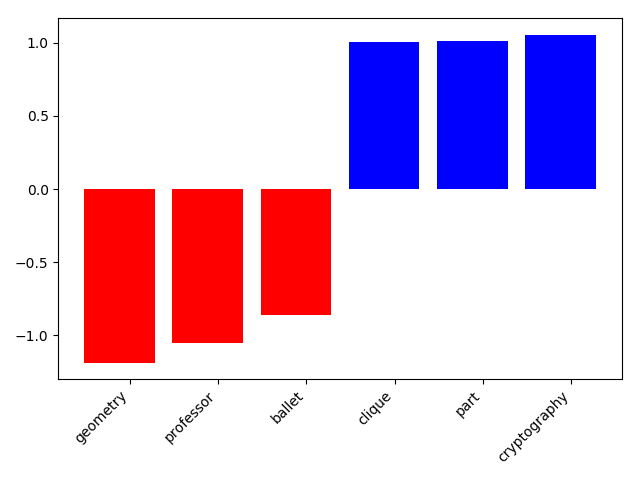
Figure 2: Top 10 profession features for “graduate students”. Blue = Top positive weights, red = Top negative weights.
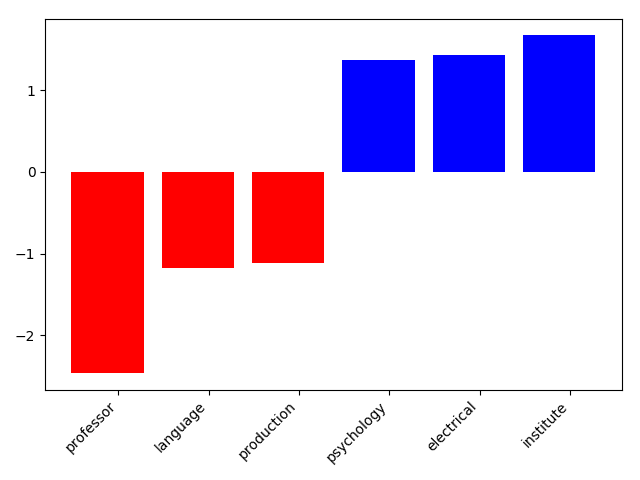
Figure 3: Top 10 profession features for “postdocs”. Blue = Top positive weights, red = Top negative weights.
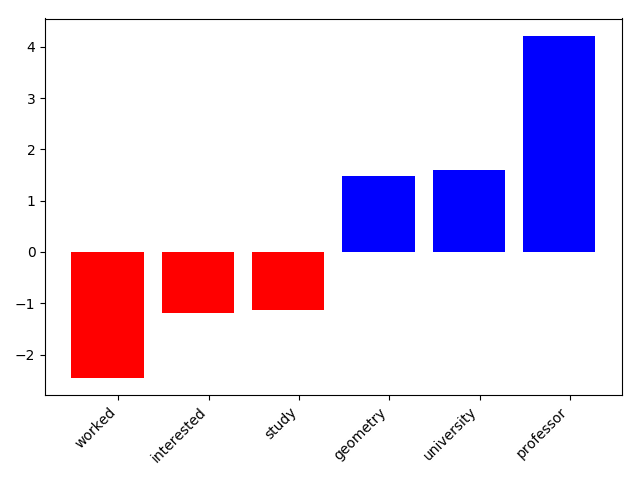
Figure 4: Top 10 profession features for “professors”. Blue = Top positive weights, red = Top negative weights.
Extract the gender¶
For the extraction of the gender, the same dataset as in Extract the profession has been used.
The data was labeled into [unknown, female, male] and again a SVM was trained. Results are shown in
Table 4: Performance of gender multiclass SVM classifier.:
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| Unknown. | 0.86 | 1.00 | 0.92 | 6 |
| Female. | 1.00 | 0.67 | 0.80 | 6 |
| Male. | 0.87 | 0.93 | 0.90 | 14 |
| avg / total | 0.90 | 0.88 | 0.88 | 26 |
| support = Number of occurrences of each label in the ground truth | ||||
The top features are shown in the figures 5, 6, 7
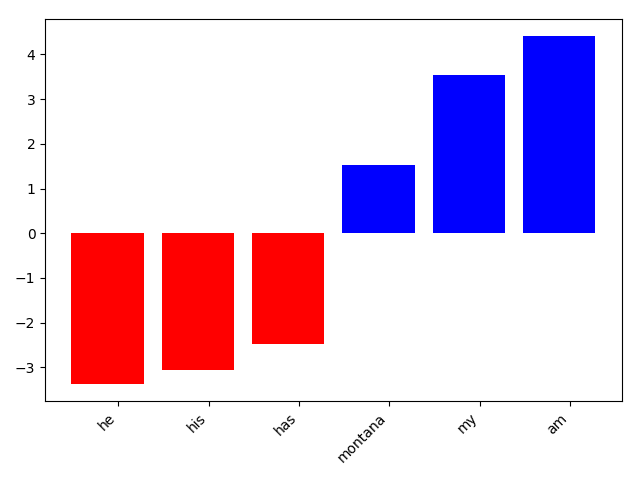
Figure 5: Top 10 gender features for “unknown”. Blue = Top positive weights, red = Top negative weights.
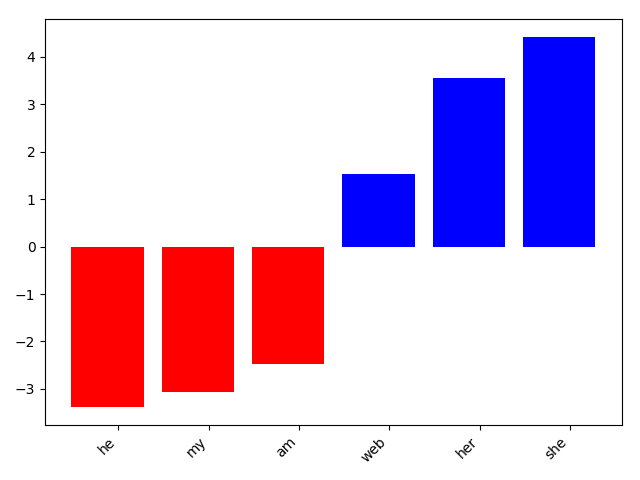
Figure 6: Top 10 gender features for “female”. Blue = Top positive weights, red = Top negative weights.
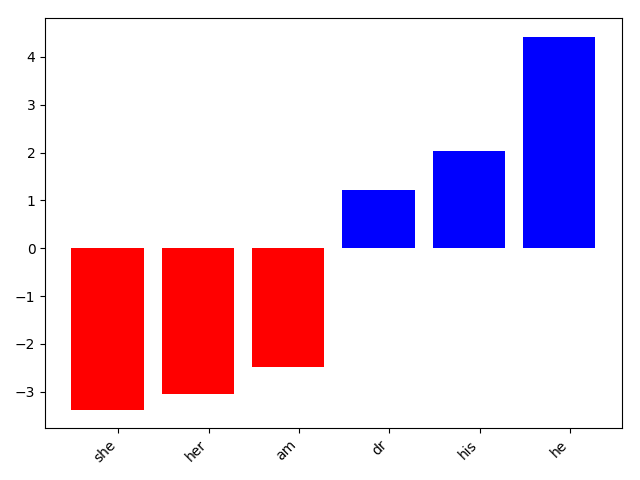
Figure 7: Top 10 gender features for “Male”. Blue = Top positive weights, red = Top negative weights.
Extract Affiliation¶
Since we retrieved the Html pages from the endSly/world-universities-csv
list of universities, the corresponding university to a person is easy to find by the url of the homepage. This is implemented in
helpers.retrieve_association_from_url and works for all homepages hosted by one of the sites in endSly/world-universities-csv.
Results¶
Using the latest classifier from data/svm_classifier.pickle we classified 186.959 positive researcher homepages
out of 38.517.248 crawled for the 9.363 universities in total which makes a rate of 0,49% of personal pages.
For this project, the CC-MAIN-2017-13 common crawl archive was used.
A quick test with 350 hand picked personal homepages of uni-freiburg revealed a coverage
of 30.39% (106 out of 350) pages.
The potential persons for which it was possible to extract a name can be found here.
Numbers¶
- Total number of domains: 9363
- Total number of fetched html sites: 38.517.248
- Size of fetched university sites (gzipped): 391.6 GiB
References¶
| [DasG2003] | (1, 2) Sujatha Das Gollapalli, Cornelia Caragea, Prasenjit Mitra, and C. Lee Giles. 2013. Researcher homepage classification using unlabeled data. In Proceedings of the 22nd international conference on World Wide Web (WWW ‘13). ACM, New York, NY, USA, 471-482. DOI: https://doi.org/10.1145/2488388.2488430 |
| [WebKB] | CMU World Wide Knowledge Base (Web->KB) project A data set consisting of classified Web pages. http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-11/www/wwkb/index.html |
| [dblp] | dblp - computer science bibliography. A database that provides open bibliographic information on major computer science journals and proceedings. http://dblp.uni-trier.de/ |
| [FGM2005] | Jenny Rose Finkel, Trond Grenager, and Christopher Manning. 2005. Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling. Proceedings of the 43nd Annual Meeting of the Association for Computational Linguistics (ACL 2005), pp. 363-370. http://nlp.stanford.edu/~manning/papers/gibbscrf3.pdf |