Introduction
This project is evaluating the design of a "search as you type" interface for special regular expressions on a large set of scanning data.The extensive and complex database of perl compatible regular expressions of the Nmap project was chosen as a practical application for this search. Its database consists of about 11300 regular expressions that represent the bulk knowledge about varying binary response characteristics of a large number of network protocols and software implementations, allowing practical fingerprinting on various levels of software, vendor and devices. An additional meta-data syntax provided by the nmap probe format augmented with standardized Common Platform Enumeration (CPE) identifiers allows for the categorization of additional information, including the ability to extract target-specific information with the help of capturing groups within the regular expressions.
Approach
Over 99% of the regular expressions in the targeted fingerprint database are front-anchored for performance and precision. Due to this fact, a two-stage approach in the form of an efficient pre-selection search data structure and a second stage with precise PCRE matching based on the robust re2 regex engine is used. Prefix trees (trie) were extensively tested for the role of a first-stage search structure, but commonly used python implementations for such data structures have proven to be inferior regarding practical search performance to general binary searches over a sorted list of results, which is consequently employed as a the first stage search mechanism for the final version of this prototype. For further information regarding those finding, see the next section.Interactive access to a very wide range of real-world device responses allows for the correction of over-constrained or mismatched nmap fingerprint probe match expressions, which is otherwise a much more time-consuming task. Additionally, the presentation of the first-stage preselection output, which is effectively the superset of the targeted data sets but also limited to those entries that share the non-dynamic regex prefix string, helps to identify elements not matched due to errors in the error-prone groups of the regular expressions.
Practical applications of this can be seen in the examples section.
List search vs. trie performance
The first stage of the probe search is based on the property of most existing search patterns to start with a fixed string prefix, which can in turn be used to exclude results without performing costly regular expression matching. Consequently, it requires a very fast method for prefix string searches, as every element of a large but static set of strings (in the order of 200k elements in the current implementation) has to be compared against the prefix string of the search pattern. Needless to say, this step is very expensive when done in a naive iterative fashion, so specially tailored methods are beneficial here.In theory, trie structures such as those provided by the marisa-trie library provide very fast data access by stepping along their internal pre-generated tree structure up to the relevant node and then returning the desired subset in bulk, utilizing their precomputed structure to avoid any read operations or comparisons with non-matching strings. For data sets with many strings that only differ in some end position, such as the telnet data targeted mainly by this project, this storage structure has the additional benefit of providing partial deduplication over the strings based on their prefixes. This adds a variant of in-memory compression that is not easily obtainable with more primitive data structures such as lists, resulting in a substantial compression factor which may lead to further performance benefits due to caching.
However, the practical performance results for the best suited trie types of the marisa-trie python wrapper have been less than satisfactory, as many of the theoretical benefits do not seem to apply for this trie implementation. Even after extensive tuning and exploration of internal optimization parameters including cache_size and num_tries, different compilation settings, optimized internal functions as well as the detection and avoidance of a significant, unpatched performance regression in marisa-trie versions >v.0.7.2. Still, the obtained search speeds are still barely usable for searches with a large number of results. Empirical data on search performance suggests a high constant cost associated with each result that is returned for a search. This issue is amplified by the lack of possibilities to limit the number of results which are returned, or ways to count the results without actually obtaining them in such a costly fashion, eg. for accurate display purposes. These factors are detrimental to the overall goal of a responsive interactive web interface, which is designed to serve only a small subset of the result data to the client, but for example still needs accurate estimations of overall result size. Additionally, several aspects of the trie structure were not as relevant as initially expected. Even the bigger probe response data set fits well into the available RAM, especially after parsing and basic deduplication over identical entries is performed. Likewise, the python/C combination does not seem to significantly benefit from any form of caching, be it implicit by the processor or explicit by the caching level included in the library.
Fortunately, the fixed nature of the probe responses string data set in question allows it to be used in the form of a list which is pre-sorted in the required lexicographical order. Such a pre-sorted list can then be very quickly searched in logarithmic time with a prefix-aware string comparison algorithm that is based on bisection. This algorithm is based on finding the first and last element matching the required prefix in complexity
O(log n)
with n = number of elements of the dataset, respectively,
marking any element in between as a valid search result. The search results (or a specific subset) can then be quickly and easily returned.
Notably, this approach also allows for precise determination of the search result size in the specified O(log n)
by
trivially calculating the number of elements included in the set, which is helpful for certain parts of this project.
To illustrate the difference between both approaches, the prefix searches for
^\xff\xfb\x01\xff\xfb\x01\xff\xfb\x01\r\n
(interactive, search #1) and
^\xff\xfb\x01\n\r\rTelnet session
(interactive, search #2)
were stepwise entered character-by-character entry for both the trie and bisect search variants, simulating real use in the search interface.
Starting with the empty prefix, all 217511 elements of the dataset are returned. This number then gradually goes down as
the expanded prefix excludes more and more elements from the list of results until the final number of 13
and 114 results is reached, respectively. Graphed in a log-log scale with the number of results returned by the search versus the time necessary to fetch the results, it is obvious that the trie search performs significantly worse for all observed result sizes:
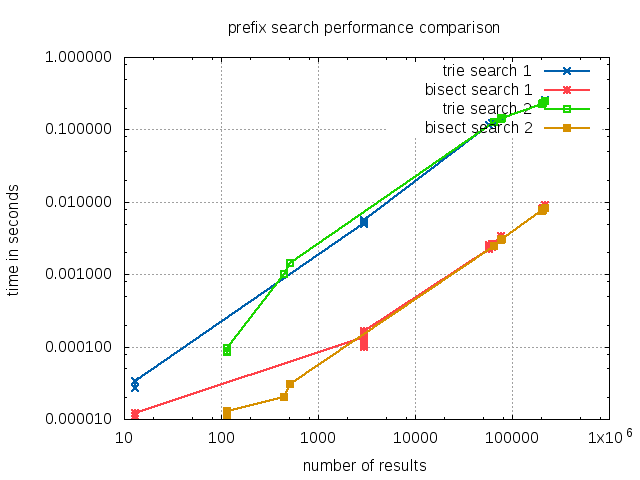
As noted before, the bisection lookup itself is very fast and well suited for regular calls to determine the size of prefix result set, as shown for the described searches:
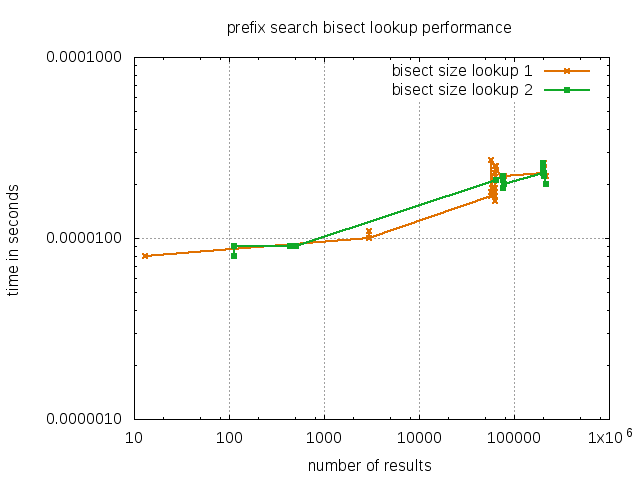
The raw csv data for those comparisons can be found here and here.
The underlying benchmark can be recreated on different platforms using the python unit tests for the prefixBisect class.