Contents
1. Project Goal
2. Background Study
2.1 SmartCalc.CTM
2.2 NoSQL database
3. Required technologies and tools
4. Working mechanism of required technologies
4.1 XQuery language
4.2 BaseX
4.2.1 BaseX GUI
4.2.2 BaseX Web Services
5. Installing and getting started
5.1 Installing BaseX
5.2 Setting up BaseX database
5.3 Install the project code into BaseX
5.4 Starting the BaseX web server
5.5 Starting with the web application
6. Functional Flow
6.1 Loading data files
6.2 Remove tags With NaN value
6.3 Add new level tag to existing data files
7. Conclusion
8. References
1. Project Goal
The XML files have fixed interface since they are the data sources for the existing analysis software and there are already about 50 working files based on measurements. For doing this analysis properly we need to develop a specific tool which will help -• adding new data tag to all material files
• visualize the imported data for error checking.
The goal of this project was to research on finding a pseudo-database handling system with a new approach (using e.g. NoSQL) and improve the performance.
2. Background Study
2.1 SmartCalc.CTM
SmartCalc.CTM is a cell to module analysis for fast and precise calculation of cell-module gains and losses for the solar module. This is a software which creates new module setup depending on given material files as input data and evaluates the effect of different materials on module efficiency and power.
To make this software work more efficiently, the background database needs to be processed more. Such as:
• The flexibility of adding additional tags to identify files required.
• Simplify the generated XML files by removing unwanted NaN values dynamically.
• The flexibility to name a tag in generated XML files if required.
• Easy importing option for XML Files into Database or exporting the database.
Doing this kind of modifications manually in the database is a complex and lengthy process. As an example- Removing NaN values from individual files are really time-consuming. That's why we were looking to build an efficient approach. Finally, we choose NoSQL database approach to overcome this constraint.
2.2 NoSQL database
NoSQL database is a kind of database technologies for storage and retrieval of data which is different from a relational database. The term NoSQL stands for "non-SQL", "non-relational" and is used to describe high-performance in non-relational databases. Comparing to relational databases, NoSQL databases are more document-oriented and distributed rather than structured.A non-relational (NoSQL) database typically does not enforce a schema rather a partition key is generally used to retrieve values, column sets or other documents containing related item attributes. This kind of database is increasingly used in big data and real-time web applications. They are widely recognized for ease of development, scalable performance, and high availability.
There are various types of NoSQL databases. Some categories are given below with popular database example
• Column store: Accumulo, Cassandra, HBase• Document database: ArangoDB, CouchDB, MongoDB, Qizx, RethinkDB
• Key-value model: Aerospike, HyperDex, OrientDB, Redis, Riak
• Graph database: AllegroGraph, Apache Giraph, Neo4J, OrientDB, Virtuoso
• XML database : EMC Documentum xDB, Berkeley DB, BaseX, Sedna
(Source)
Reasons to use NoSQL database over Relational database
When the data requirements are not clear then we may have to deal with massive amounts of unstructured data. In this case, we have to think about schema-less database option over a traditional relational database. As we know relational database should have to be well formed as a database table with appropriate linking or joining attributes. Here comes the idea of using NoSQL database. Instead of tables, NoSQL databases are document-oriented. It offers the advantages of analyzing non-structured data which can be stored in a single document that can easily be used as target data source.The XML databases for SmartCalcCTM software, are not always well structured. Often we have to deal with non-structured measurements data in the huge amount of XML data files. The processing and analyzing of these unstructured data lead us to a schema-less development. Here NoSQL databases, an alternative to relational databases, comes to a solution which is appropriate for our project.
Benefits of using NoSQL database
NoSQL databases are different in terms of used data structures from those in relational databases which made some operations faster in NoSQL and gave more flexibility to us during the process of development. There are some other benefits of using NoSQL Databases which we considered here like low latency and high scalability of NoSQL databases. NoSQL databases give the ease access to execute queries through APIs, even without understanding the underlying architecture of database system. From a developer point of view, it made our development quicker than relational databases where we have to deal the relationship with applications written in Python, Java, PHP programming languages.3. Required Technologies
This project is built on the open source tool BaseX. We created some separate functionalities to handle the XML files (described later). We have used XQuery as a server-side processing language. In some cases, JQuery and JavaScript have been used. For editing query, we used BaseX GUI including several visualizations. We have used BaseX HTTP Server to access REST, RESTXQ and WebDAV Services of BaseX to store database and login authorization.4. Working mechanism of required technologies
4.1 XQuery Language
XQuery is a fully typed functional programming language. It is a language for querying XML data with the flexibility of selecting and manipulating specific parts and attributes of XML documents. XQuery is built on XPath expressions and supported by all major databases. It gives a result of an extremely compact code, which can hardly be smuggled into mistakes. On the other hand, very different architectural sections are possible. You can use XQuery same as SQL. Only the accesses to the data are written with XQuery, everything else is written in Java, Python or C #.
Simple "Hello Query" example of XQuery
1 2 3 4 5 6 | xquery version "3.0" encoding "UTF-8"; let $msg := 'Hello XQuery' return <results timestamp="{current-dateTime()}"> <message>{$msg}</message> </results> |
Simple XQuery with FLWOR expression
1 2 3 | for $x in doc("books.xml")/bookstore/book where $x/price>30 return $x/title |
In the above code segment, we are using XQuery FLWOR expression to select the books under the bookstore tag from a given XML file and the result will be stored into $x variable. The condition here specifies to select the book element with a price greater than 30. Return expression specifies a return value of the queried result.
4.2 BaseX
BaseX is a light-weight XML Database solution to store and query semistructured XML data (and thus a NoSQL database). It works as an XQuery processor which is written in Java. It is platform-independent and is available under the free BSD license. It supports a wide range of APIs: REST, WebDAV, XML: DB, XQJ; Java, C #, Perl, PHP, Python, and others. BaseX has a GUI to visualize XQuery XML data and to create an XML database. BaseX GUI is also used to develop XQuery scripts. BaseX can store individual XML documents with up to 4 billion nodes with a file size of more than 10 GB.4.2.1 BaseX GUI
The BaseX GUI is the visual interface of BaseX. It gives an idea of combining XQuery with BaseX. It provides a visual frontend which allows users to explore data and evaluate XQuery expressions interactively in real-time. Real-time Execution of XQuery expressions can be executed and the results are visualized immediately. This editor has syntax highlighting feature along with error feedback while debugging.4.2.2 BaseX Web services
BaseX provides access to stored database resources and to the XQuery engine via REST, RESTXQ services. The services can be deployed in three different ways:
• as a standalone application by running the BaseX HTTP Server,
• as web servlets in a J2EE Servlet Container, and
• using Maven for development purposes.
REST
REST (Representational State Transfer) is a mechanism which facilitates a simple and fast access to databases through different HTTP methods like GET, PUT, DELETE, and POST. These methods are used to interact with the database. REST access XML database and its resources.RESTXQ
RESTXQ is a new API that facilitates the use of XQuery as a Server Side processing language for the Web. It creates XQuery Web Services. RESTXQ has been inspired by Java’s JAX-RS API: it defines a pre-defined set of XQuery 3.0 annotations for mapping HTTP requests to XQuery functions, which basically implements HTTP responses. As of Version 7.2, RESTXQ is supported by BaseX.BaseX web sends requests expressed in XQuery and retrieves results (serialized as XML, binary or JSON) from the processing engine. A system overview of BaseX Web operation
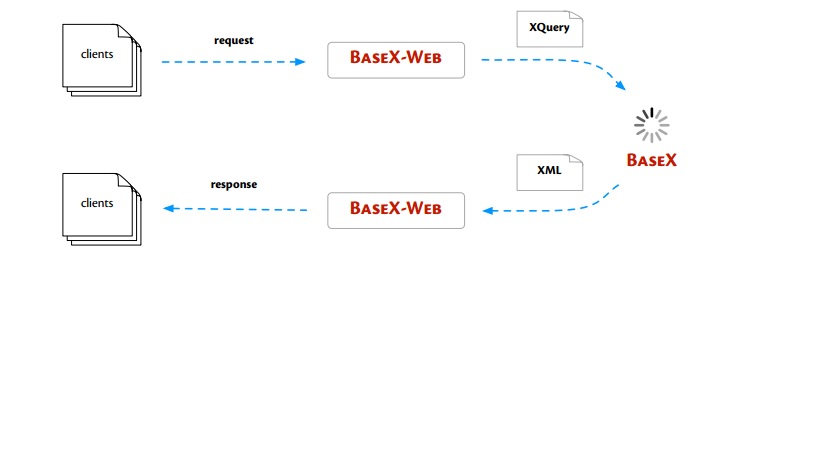
(source)
5. Installing and getting started
5.1 Installing BaseX
Three different versions of BaseX are available from where you can choose one according to your goal. Here we worked with the Windows installer.You can download the latest version from here. Note that, you should have the latest version of Java installed on your system since baseX needs Java runtime environment.For a successful installation, the installer file "BaseX.exe" has to be run by following the instructions to complete the process. A desktop icon will appear for BaseX.
5.2 Setting up BaseX database
A practical idea about BaseX can be found by using the BaseX GUI. The GUI can be opened by double-clicking on the BaseX GUI icon. A short description of the GUI is given in section 4.2.1. Then it is possible to set up BaseX database here with new database option. This GUI gives us the flexibility to perform different queries. A working example of BaseX GUI is given below-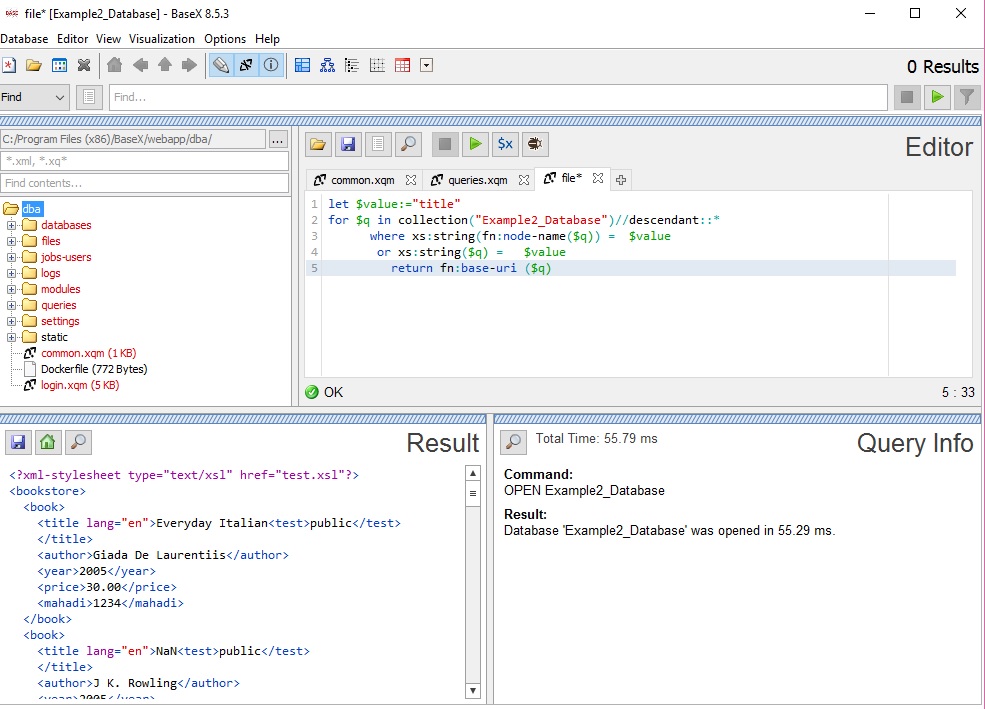
5.3 Setting project code inside BaseX
To work with the implemented functions, the zipped file from Codes section has to be downloaded. There will be a bunch of folders in the directory where BaseX is installed. The next step is to copy the folder named "webapp" (which was downloaded from the code section) and replace it in the directory over the existing one.5.4 Starting the BaseX web server
BaseX can be used as Web Application with the HTTP Server. BaseX HTTP server provides access to the REST, RESTXQ services which are accessible via http://localhost:8984/. We can start the BaseX HTTP Server by running basexhttp or basexhttp.bat scripts. After that, we have to visit the URL http://localhost:8984/dba for database administration. Below we have an overview of login to BaseX Server.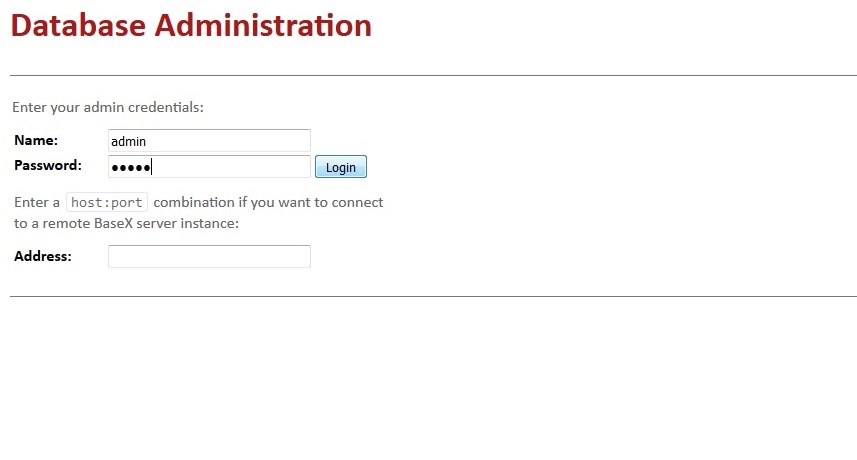
Once the welcome page is loaded, an authentication has to be done by entering the name and password of an admin user (admin/admin). After the first login, the user can set new user credentials from Users panel.
5.5 Starting with the web application
DBA interface contains all databases listed on the left side. Once you select a specific database, you will be redirected to another window. On the top left side, you will find all functions to modify the database (screenshot is given bellow)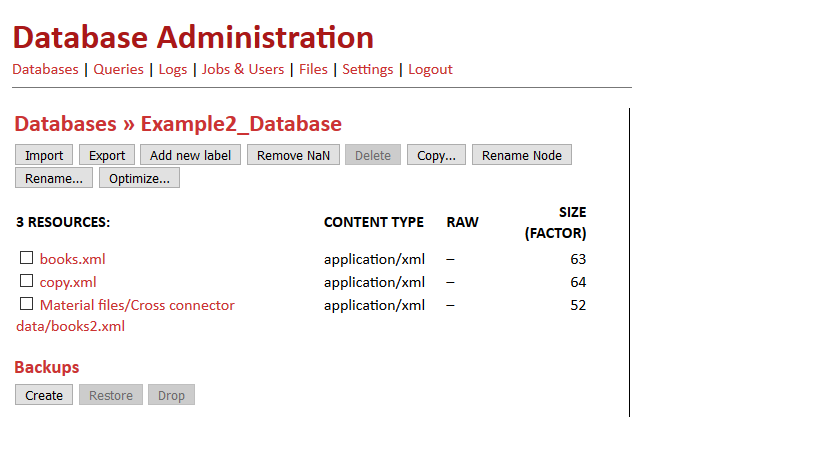
6. Functional Flow
Here we will discuss in details about a couple of functionality which has been implemented during this project development.6.1 Loading data files
We developed a function for importing single XML file for existing database following sub folder directory. An import button is placed on the web- interface to add more XML file. When we will click on this button, it will trigger add-post() function from RestXQ source code (which is given below).In this function, we have to browse the specific file from the directory and select it. We can also add the path to save the file in the database when using the data list function. This function can also be checked for empty input value and give an error message if required.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | function _:add-post( $name as xs:string, $opts as xs:string*, $path as xs:string, $file as map(*), $binary as xs:string? ) { cons:check(), try { let $key := map:keys($file) let $path := if(not($path) or ends-with($path, '/')) then ($path || $key) else $path let $content := $file($key) return if(not($key)) then ( error((), "No input specified.") ) else if(util:eval('db:exists($n, $p)', map { 'n': $name, 'p': $path })) then ( error((), 'Resource already exists: ' || $path || '.') ) else ( if($binary) then ( util:update('db:store($n, $p, $c)', map { 'n': $name, 'p': $path, 'c': $content }) ) else ( let $xml := try { convert:binary-to-string($content) } catch * { error($err:code, replace($err:description, '^.*\): ', '')) } return util:update('db:add($n, $x, $p)', map { 'n': $name, 'x': $xml, 'p': $path }) ), db:output(web:redirect($_:SUB, map { 'name': $name, 'path': $path, 'info': 'Added resource: ' || $name })) ) } catch * { db:output(web:redirect("add", map { 'error': $err:description, 'name': $name, 'opts': $opts, 'path': $path, 'binary': $binary })) } }; |
6.3 Add new lebel tag to existing data files
For adding a new label in the files, a function named "addlabel()" is built here. This function takes some parameters as an input• Database name as $name variable
• Value to insert in new label as $labelvalue variable
• the place to add the new node among existing node names as $nodenam
• lastly the new label as $label variable.
The XQuery is used here to insert the new label which specifies a matching condition between the existing node name and given place to add the new label. It will add the newly inserted label where the match is found.
Finally, the output is directed to the web and gives a result that "New node was added". Here we used 'try and catch' to get the exception and empty input value which is also checked here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | function _:addlabel( $name as xs:string, $label as xs:string, $labelvalue as xs:string, $nodename as xs:string ) { cons:check(), try { let $key := $label return if(not($key)) then ( error((), "No search input.")) else( util:update("let $node:= concat('<',$label ,'>', $labelvalue,'</',$label ,'>') let $newnode:=fn:parse-xml($node) for $q in collection($n)//descendant::* where xs:string(fn:node-name($q)) = $nodename return insert node $newnode as last into $q", map { 'n': $name,'label': $label,'labelvalue': $labelvalue,'nodename': $nodename} )), db:output(web:redirect($_:SUB, map { 'info': 'New node was added.', 'name': $name, 'label': $label })) } catch * { db:output(web:redirect("addlabel", map { 'error': $err:description, 'name': $name, 'label': $label })) } }; |
7. Conclusion
The SmartCalcCTM is a software to analyze cell to module ratio in a solar cell. It has to process the XML database which is inconvenient due to having some lack of functionality. The number of an available online tool for doing such modification from raw data is still not enough. During this project, we build a NoSQL database approach to overcome these difficulties. The idea here is to handle the modification more efficiently and quickly of such big XML files which have been implemented by defined functionality in a handy way. This is the point of interest for the people who like to work with widely used XML database technology of data modification.8. Referrences
http://files.basex.org/publications/dummies/BaseX_for_dummies.pdfhttp://files.basex.org/releases/7.2.1/BaseX721.pdf
Seiferle [2012], Implementing Web Applications Using XQuery
http://db.inf.uni-tuebingen.de/staticfiles/publications/xquery-processors.pdf
http://www.inf.uni-konstanz.de/dbis/teaching/ws0708/dbissem/BaseXInside.pdf http://docs.basex.org/wiki/Startup#BaseX_Standalone
http://www.w3schools.com/xml/xquery_intro.asp
http://files.basex.org/releases/7.2.1/BaseX721.pdf
http://files.basex.org/publications/xmlprague2013/2013/Develop-RESTXQ-WebApps-with-BaseX.pdf